
AI開発の常識を根底から覆す、驚愕のニュースが飛び込んできた。中国の新星AI企業DeepSeekが、なんと従来の95%もの開発コストを削減し、しかもOpenAIのGPT-4に匹敵、あるいは凌駕する性能の大規模言語モデルを開発することに成功したのだ。
これまで、最先端AIモデルの開発には、数億ドル(数百億円)規模の巨額な投資と、数ヶ月から数年単位の長い時間が必要とされてきた。しかし、DeepSeekは、わずか550万ドル(約8億円)と2ヶ月という、桁違いの低コスト・短期間でこれを実現。この革命的な成果は、AI開発の民主化を加速させ、世界のテクノロジー業界に激震をもたらす可能性を秘めている。
一体、DeepSeekは何をどう変えたのか?その技術的革新の秘密と、AI業界全体へのインパクトを徹底解剖する。
▶︎1億ユーザー獲得競争:DeepSeekの圧倒的スピード
DeepSeekの勢いは、ユーザー獲得スピードにも表れている。以下の表は、主要なサービスが1億ユーザーを獲得するまでにかかった時間を比較したものだ。
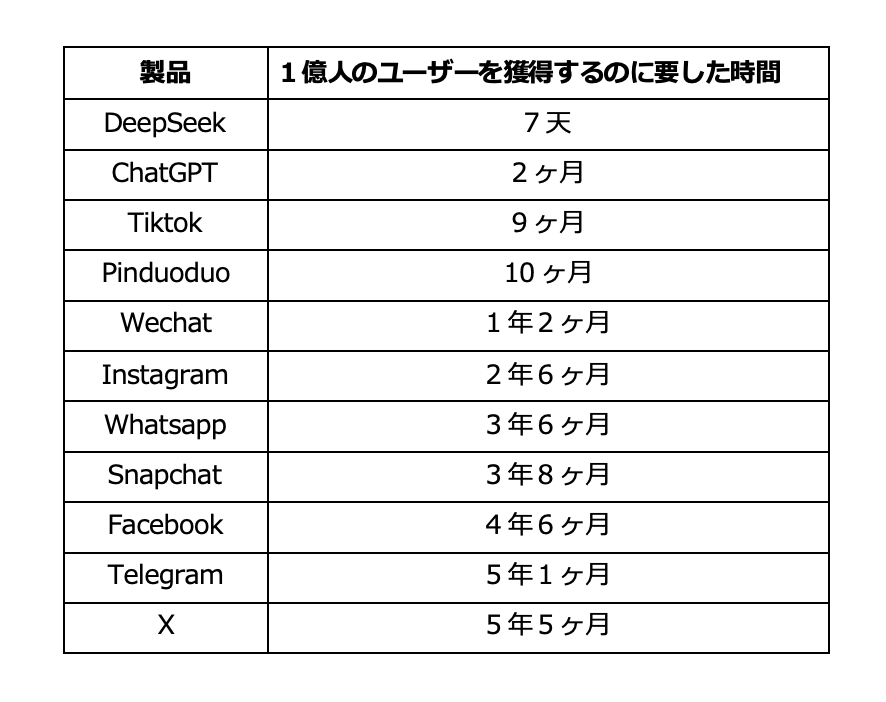
表:各製品が1億人のユーザーを獲得するのに要した時間
DeepSeekは、ChatGPTを大幅に上回る、わずか7日間で1億ユーザーを獲得。この驚異的な数字は、DeepSeekのモデルがいかに高性能で、ユーザーニーズに応えているかを如実に示している。
▶︎DeepSeekとは? – 中国AI界の新星
DeepSeekは、2023年に設立されたばかりの、中国の人工知能研究企業だ。オープンソースの大規模言語モデル(LLM)開発に特化し、梁文锋(リャン・ウェンフォン)氏によって設立。中国のヘッジファンド 幻方量化(High-Flyer) からの資金提供を受けている。
設立以来、DeepSeekは以下の主要なAIモデルを発表してきた:
・DeepSeek-V2 (2024年5月): 高性能かつ低価格で、中国国内のAIモデル価格競争の火付け役となった。
・DeepSeek-V3 (2024年12月): 6710億個のパラメータを持ち、約558万ドル(約8億円)のコストでトレーニング。性能面ではOpenAIのGPT-4に匹敵すると評価されている。
・DeepSeek-R1 (2025年1月20日): 最新の完全オープンソースモデルで、OpenAIのo1モデルに匹敵する性能。ウェブ、アプリ、APIを通じて利用可能。
DeepSeekは、情報提供、テキスト処理、学習サポート、技術サポート、日常会話など、多様なタスクに対応できる。ただし、データは2023年12月時点のものであり、最新ニュースの提供や個人情報への対応はできない。また、複雑な計算結果は確認を推奨する。
▶︎DeepSeekのコア優位性:なぜ低コスト・高性能が実現できたのか?
DeepSeekの成功の鍵は、以下の3つのコア優位性にある。
圧倒的な低コスト
・550万ドルの開発費: GPT-4の開発費(数億ドル)のわずか5%-10%。
・アルゴリズム最適化: 計算のスパース化(MoEアーキテクチャ)などにより、計算量を大幅削減。
・ハードウェア効率化: NVIDIA H800 GPUクラスターと自社開発の分散トレーニングフレームワーク(DeepSpeed-Coralなど)により、GPU利用率を業界平均(75%)を大きく上回る92%に。
・データ効率の革新: DataQualityNetツールにより、有効データ割合を業界平均の30%から65%に向上。
驚異的な開発スピード
・2ヶ月でトレーニング完了: 従来の大規模モデル(6〜12ヶ月)を大幅に短縮。
・3D並列技術: データ並列、パイプライン並列、テンソル並列を組み合わせ、トレーニング時間を極限まで短縮。
・ダイナミックチェックポイントメカニズム: 故障からの迅速な復旧を可能にし、トレーニングの連続性を確保。
GPT-4に匹敵する高性能
・MoEアーキテクチャ: 推論時にパラメータの20%のみを活性化し、計算を効率化。
・カリキュラム学習戦略: モデルの学習効率を3〜5倍向上。
・技術革新のキーポイント:DeepSeekの秘密兵器
DeepSeekの革新を支える、具体的な技術的キーポイントを解説する。
アルゴリズムの最適化
・スパース計算: MoEアーキテクチャの動的ルーティングメカニズムにより、一部のニューロンのみを活性化。計算量を60%削減。
・混合精度トレーニング: FP16とFP8の量子化技術を組み合わせ、メモリ使用量を40%削減しつつ、モデル精度を維持。
エンジニアリングの実践
・分散トレーニングフレームワーク: 自社開発のDeepSpeed-Coralは、1024枚のGPUクラスターで89%の拡張効率を実現。
・フォールトトレランスメカニズム: ダイナミックチェックポイント技術により、故障からの復旧時間を時間単位から分単位に短縮。
データ効率
・高品質データフィルタリング: DataQualityNetツールで低品質データを迅速に除去。
・合成データ生成: 生成AI技術で大量の高品質な合成データを生成し、トレーニングデータを拡充。
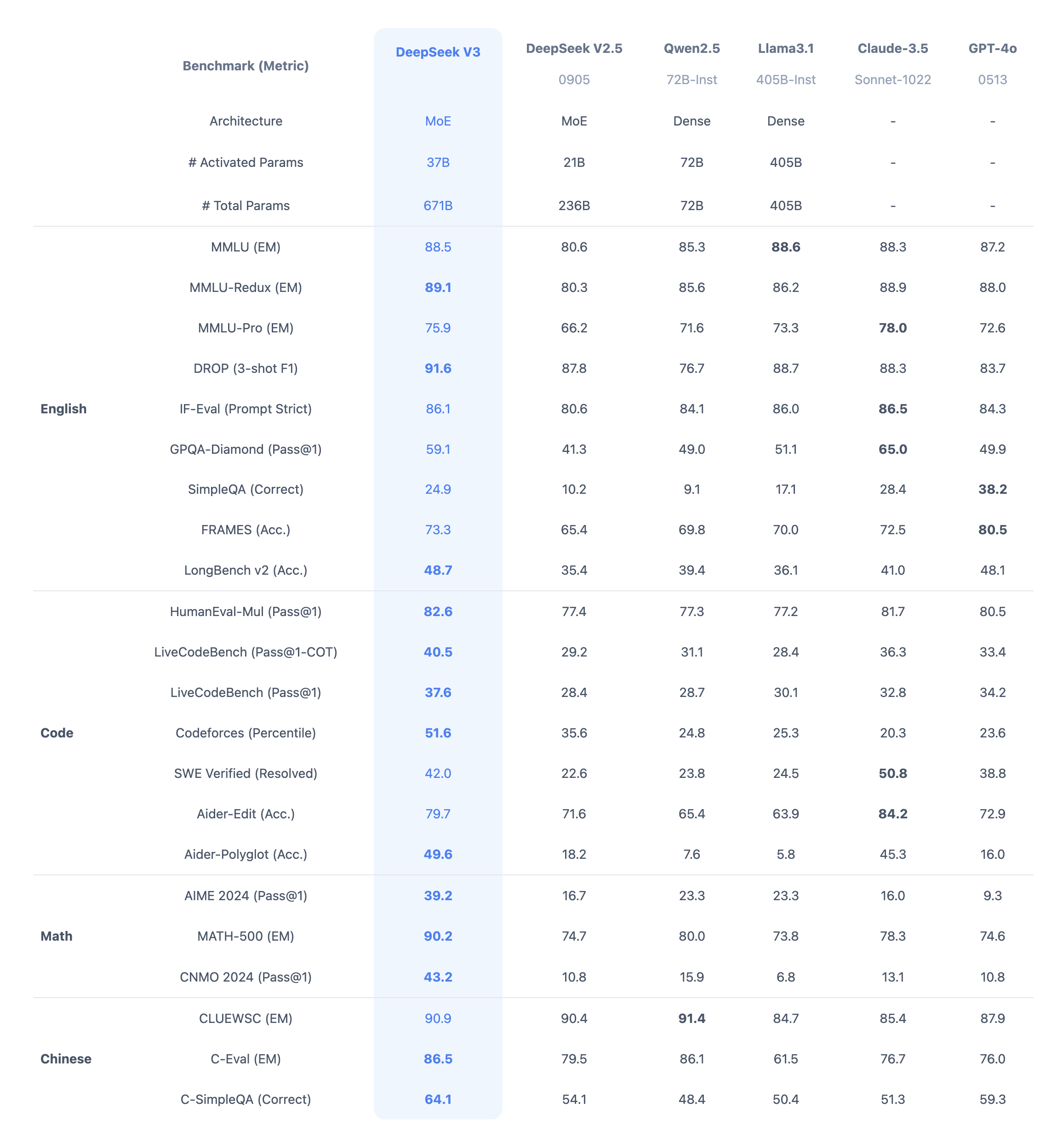
▶︎業界への影響と将来展望:AI開発の民主化が始まる
DeepSeekの登場は、AI業界に以下の様な大きな影響を与える。
・参入障壁の劇的低下: 大手企業だけでなく、中小企業やスタートアップでも、低コストで高性能なAIモデルを開発できるようになる。
・ハードウェアエコシステムの多様化: 世界的なGPU不足や米国の規制の中、DeepSeekはアルゴリズム最適化で対抗。中国国産ハードウェアのエコシステム構築を加速させる。
・技術の多極化: 世界のAI開発が、より多くの国や地域に分散し、それぞれのニーズに合った技術が生まれる。
・商業化の加速: エッジコンピューティングや、医療、金融、教育などの特定分野へのAI導入が加速する。

▶︎課題とリスク:乗り越えるべき壁
DeepSeekは大きな可能性を秘める一方、以下の課題も抱えている。
・ハードウェアサプライチェーンのリスク: 米国の輸出規制による高性能GPUの供給制限。
・エネルギー効率のボトルネック: モデル規模拡大に伴う、トレーニングのエネルギー消費増加。
・アルゴリズムの限界: MoEアーキテクチャは推論の複雑さを増す可能性があり、商業化への課題となる場合がある。
▶︎まとめ:DeepSeekが切り開くAIの未来
DeepSeekは、低コスト・高効率の革新的なAI開発モデルによって、世界のAI業界に新たな地平を切り開いた。その技術的ブレークスルーは、AI開発の民主化を加速させ、より多くの人々がAIの恩恵を受けられる未来を予感させる。
ハードウェアエコシステムの整備とアルゴリズムの継続的な最適化を進めることで、DeepSeekは、さらに多くの分野で商業化を成功させ、AI技術の普及を力強く推進していくだろう。DeepSeekの快進撃は、まだ始まったばかりだ。
最新情報をお届けします
Twitter でbizchinablogをフォローしよう!
Follow @bizchinablog

コメントはこちら